

What are Object Recognition and Object Tracking? What do we need to put them into practice? In this article, you will find a brief overview of these two fundamental artificial vision techniques in many applications with drone imagery.
Object Recognition
The term “object recognition” is generally used to describe a collection of computer-vision-related tasks that equip a machine with artificial intelligence in order to identify objects in digital photographs.
Such a complex topic can be smoothly understood by comparing it with the human cognitive process.
![Figure1: The IT cortex distinguishes between different objects. (Image: Chelsea Turner, MIT [1])](https://www.geodatalab.it/wp-content/uploads/2022/06/Figure1-300x200.jpg)
Figure1: The IT cortex distinguishes between different objects. (Image: Chelsea Turner, MIT [1])
We can, therefore, sum up the comparison among machine and human object recognition systems with the following matching:
- Eye (Retina) → Optic Sensor
- Brain → Processing Unit
- IT Cortex → Computer Vision Algorithms
- “Patches” of neurons → Dataset
How does all this happen on a machine?
Like mentioned before, the term “object recognition” refers to a collection of tasks. In particular, as suggested in paper [2], we can use it “to encompass both image classification (a task requiring an algorithm to determine what object classes are present in the image) and object detection (a task requiring an algorithm to localize all objects present in the image).”
First Step: Image Classification
The first step in object recognition is the image classification phase (often called Image Recognition). The goal is to classify the image by assigning it to a specific class.
Thanks to recognition algorithms pre-trained on a given dataset, the machine will predict which type of object is the most likely one, as shown in Figure 2, where we suppose that our dataset has just three object categories: “truck”, “bus” and “car”. In this case the object was classified as a “car”.
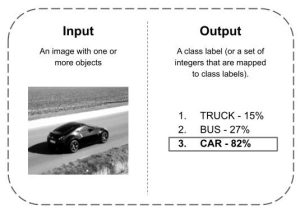
Figure 2: Image Classification or Image Recognition
Second Step: Object Detection
The term “object detection” refers to the ability to locate an object inside an image by providing the bounding box and a class object (Figure 3). However, a distinction between object localization and detection is made in the literature.
An object localization algorithm will produce a category list of objects in the picture with the bounding box related to only one item for each category. That is the main difference compared to object detection algorithms. These last ones do not have this limitation. Indeed, all the instances of the same category present in the same picture can be detected and localized.
In real applications, pictures contain several objects to be detected (i.e. traffic images) , that’s why object detection algorithms are continuously being fine tuned and developed.
YOLO5 is one of the most advanced open source detectors [3].
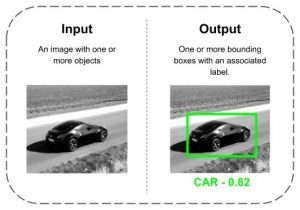
Figure 3: Object Detection
So far we have illustrated the two main tasks included in an object recognition process. So what makes all this happen on a machine? Datasets are essential. Accurate object detection is strictly related to datasets [4]. A dataset contains many pieces of data needed to train an algorithm to find predictable patterns. Once a model is trained, the machine will use it to make a prediction on a given digital photo, exploiting the weights of the pre-trained model.
A well-known pre-trained model downloadable from the web is DarkNet-53 [5]. This convolutional neural network is 53 layers deep. The available online version has been pre-trained on more than a million images from the ImageNet database, and it can classify images into 1000 object categories.
Object Tracking
Object tracking is the computer vision task that aims to locate an object in subsequent video frames. There are mainly two levels of object tracking:
- Single Object Tracking (SOT)
- Multiple Object Tracking (MOT).
After having detected and labeled one or more objects in a video, the aim is to follow its or their movements in time (see Figure 4).
![Figure 5 - Object Tracking [5]](https://www.geodatalab.it/wp-content/uploads/2022/06/Figure5.png)
Figure 4 – Object Tracking [6]
To face this problem, many modern trackers use techniques that perform model training online and at runtime. In contrast to an offline classifier which may need thousands of examples to train a model, an online classifier typically gets trained using very few examples at run time.
Different tracking algorithms have been developed to suit specific applications. We plan to offer a comparison among the main ones in future articles. At GeoDataLab, we dealt with object recognition and tracking. If you want to know more about it, visit the projects section.
Fonti
[1] Trafton A., “How the brain distinguishes between objects” MIT News Office, March 13, 2019
[2] Russakovsky O., Deng J., Su H., Krause J., Satheesh S., Ma S., Huang Z., Karpathy A., Khosla A., Bernstein M. Berg A. and Fei-Fei, L. “ImageNet Large Scale Visual Recognition Challenge” 2014 arXiv Computer Vision and Pattern Recognition
[3] Brownlee J., “A Gentle Introduction to Object Recognition With Deep Learning”, May 22, 2019 in Deep Learning for Computer Vision
[4] Sydorenko I., “What Is a Dataset in Machine Learning: Sources, Features, Analysis” – April 4, 2021.
[5] DarkNet-53 convolutional neural network
[6] Gulraiz Khan, Zeeshan Tariq and Muhammad Usman Ghani Khan, “Multi-Person Tracking Based on Faster R-CNN and Deep Appearance Features” May 20th, 2019 DOI: 10.5772/intechopen.85215

SW Engineering