

Quando si parla di intelligenza artificiale oggi, si parla anche di “machine learning”, “deep learning”, reti neurali e di moltissimo altro ancora. Qual è la relazione tra queste tecnologie? Cosa le differenzia? In questo articolo, offriremo un quadro di insieme e faremo il punto dei problemi trattati attraverso le diverse tecniche.
AI, ML e Deep Learning
Come il termine stesso suggerisce, l’Intelligenza Artificiale (IA) mira a fare in modo che una macchina imiti il comportamento umano ed esegua delle attività come le eseguirebbe un uomo, ma su una scala e una latenza non umanamente possibili. In altre parole, l’IA mira all’automatizzazione del processo decisionale passando attraverso delle trasformazioni di dati realizzate da algoritmi che seguono determinate regole per produrre una risposta specifica [1] [2] [3].
![Relazione tra AI, ML e DL [4]](https://www.geodatalab.it/wp-content/uploads/2021/04/AI-ML-DL-600x338.jpg)
Relazione tra AI, ML e DL [4]
Per completare il quadro riassunto in Figura 1, il deep learning è, a sua volta, un sottoinsieme dell’apprendimento automatico che consente ai computer di risolvere problemi più complessi, come la visione artificiale e l’elaborazione del linguaggio naturale [5]. Per capire meglio in che modo il deep learning differisce dalle tradizionali tecniche di machine learning, diamo prima uno sguardo a queste ultime.
Tecniche di ML
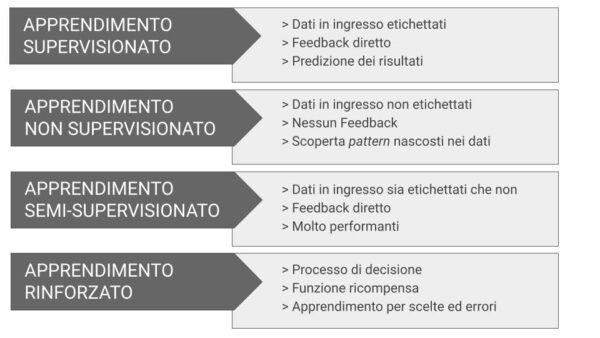
Come mostrato in Figura 2, le tecniche di ML sono comunemente suddivise in quattro categorie: apprendimento supervisionato, non supervisionato, parzialmente supervisionato e rinforzato.
L’apprendimento supervisionato utilizza esempi etichettati per prevedere eventi futuri da dati mai visti prima [2] [4] [6]. Può essere utilizzato in numerosi contesti applicativi, come per esempio: la classificazione di immagini, il riconoscimento facciale, la previsione delle vendite e del tasso di abbandono dei clienti, il rilevamento di spam [8].
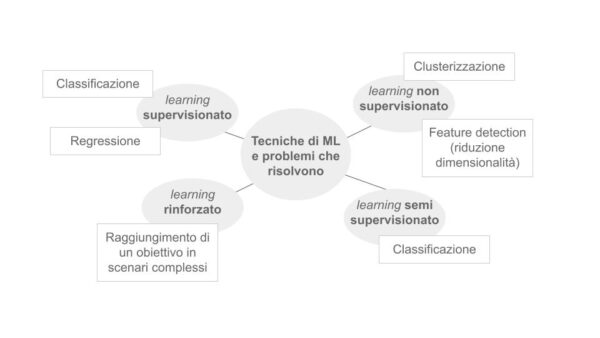
L’apprendimento supervisionato risolve problemi di regressione e di classificazione. La differenza tra i due tipi di problemi è che durante una classificazione, i dati in ingresso sono mappati su un insieme discreto di classi o label. In altre parole, tali algoritmi chiedono al modello di fare una scelta tra due o più classi. Alcuni esempi sono: Logistic Regression e Support Vector Machine (SVM).
Nel caso di regressione, invece, i dati in ingresso sono mappati su valori reali continui. Le regole in questo caso sono quindi delle funzioni matematiche continue. Tali algoritmi, in sostanza, chiedono al modello di predire un numero reale. Alcuni esempi sono: Learning Vector Quantization (LVQ), LARS Lasso, Elastic Net, Random Forest, AdaBoost e XGBoost.
Gli algoritmi Naive Bayes, Decision Tree, K-Nearest Neighbors (KNN) possono risolvere sia problemi di classificazione che di regressione.
Tecniche di ML
Se l’apprendimento supervisionato parte da una conoscenza iniziale per i processi di classificazione e regressione, in quanto i dati in ingresso sono già etichettati, l’apprendimento non supervisionato viene utilizzato quando non si possiede questa conoscenza a priori. Gli algoritmi che rientrano in questo gruppo, infatti, lavorano su dati non etichettati con lo scopo di scoprire, derivandola dai dati, una funzione che descriva modelli nascosti nei dati stessi (hidden patterns) [2] [4] [6]. Tali algoritmi fanno questo confrontando i dati tra loro e ricercando similarità o differenze. Questo tipo di apprendimento viene utilizzato nei motori di ricerca (per capire l’attinenza di una ricerca con un insieme di pagine web), per il rilevamento di anomalie nel traffico di rete, per la segmentazione dei clienti e il suggerimento di contenuti.
In termini più tecnici, possiamo dire che gli algoritmi di apprendimento non supervisionato risolvono problemi di clusterizzazione e di individuazione e riduzione di dimensionalità. Un problema di clustering o clusterizzazione, chiede al modello di trovare gruppi di dati simili. L’algoritmo più popolare che rientra in questa classe è il K-Means Clustering, ma ce ne sono anche molti altri, tra cui: Mean-Shift Clustering, Density-Based Spatial Clustering of Applications with Noise (DBSCAN), Gaussian Mixture Models (GMM) e Hierarchical Agglomerative Clustering (HAC).
Il problema di riduzione di dimensionalità chiede ad un modello di eliminare o combinare tra loro le variabili che hanno nessuno o poco effetto sul risultato. Tra gli algoritmi usati per questi fini: Backward Feature Elimination, Forward Feature Selection, Factor Analysis e Principal Component Analysis (PCA).
Tipi di problemi risolti dalle tecniche di ML
L’apprendimento parzialmente supervisionato utilizza per l’addestramento del modello sia dati etichettati che non etichettati. I risultati migliorano le performance nei problemi di classificazione [1] [8] soprattutto per scenari applicativi come la disambiguazione delle parole (Word Sense Disambiguation) [9] e il riconoscimento della scrittura a mano [8].
L’apprendimento rinforzato, infine, fa uso di metodi di apprendimento autonomi che eseguono azioni all’interno di un ambiente per massimizzare una funzione “ricompensa” lungo una particolare dimensione e attraverso un processo per tentativi ed errori.
Tale apprendimento viene utilizzato in una vasta gamma di scenari applicativi tra cui la gestione delle risorse in un cluster di computer, il controllo della segnaletica semaforica per risolvere problemi di congestione del traffico, la configurazione automatica di sistemi Web [10].
Esempi di algoritmi che implementano questo tipo di apprendimento sono il Q-learning e il processo decisionale di Markov [2] [4] [6].
Deep Learning e Reti Neurali
Gli algoritmi di deep learning rientrano nelle tecniche di machine learning non supervisionato, ma differiscono da esse per il tipo di dati utilizzati e per il modo in cui procedono nell’apprendimento.
Le tecniche di deep learning possono apprendere automaticamente da dati come immagini, video o testo, senza introdurre regole codificate manualmente [1] [4]. Inoltre, il deep learning utilizza reti neurali artificiali a più livelli per fornire un’accuratezza all’avanguardia, costruendo concetti complessi da concetti più semplici in attività come il rilevamento di oggetti, il riconoscimento vocale, la traduzione della lingua e così via [4].
In conclusione possiamo dire che l’Intelligenza Artificiale è una materia oggetto di ricerca e studio già a partire dagli anni 50. Pertanto, i suoi sviluppi risultano complessi e articolati. Il machine learning e il deep learning si innestano in questo quadro come step di sviluppo successivi dell’Intelligenza Artificiale, che mirano a risolvere problemi diversi attraverso algoritmi e tecnologie diversi.
Per un ulteriore approfondimento, suggeriamo la lettura di questo articolo, che offre un quadro generale degli sviluppi dell’IA in tre epoche, secondo una prospettiva sviluppata dal dipartimento della difesa statunitense.
Coautore: Chiara Sammarco
Fonti
[1] Géron A. Hands-On Machine Learning with Scikit-Learn and TensorFlow. O’Reilly Media, 2019, p. 2.
[2] Oracle Big Data Blog, What’s the Difference Between AI, Machine Learning, and Deep Learning? (Ultima consultazione: 12/02/2021).
[3] TensorFlow, Introduzione al Machine Learning (Ultima consultazione: 12/02/2021).
[4] Lunga, D. (2019). Artificial Intelligence Tools and Platforms for GIS. The Geographic Information Science & Technology Body of Knowledge (4th Quarter 2019 Edition), John P. Wilson (ed.). DOI: 10.22224/gistbok/2019.4.16
[5] Martin Heller, Deep learning: come funzionano gli algoritmi che imitano il cervello umano, Computer World (Feb. 2020)
[6] Tohidi N. A Review of the Machine Learning in GIS for Megacities Application. DOI: 10.5772/intechopen.94033.
[7] Martin Heller, Deep learning vs. machine learning: Understand the differences, InfoWorld
[8] Ben Dickson, What is semi-supervised machine learning? (January 4, 2021)
[9] Anh-Cuong Le, Akira Shimazu, and Le-Minh Nguyen, Investigating Problems of Semi-Supervised Learning for Word Sense Disambiguation, December 2006 DOI: 10.1007/11940098_51
[10] Applications of Reinforcement Learning in Real World, Towards Data Science
