

L’idea alla base dell’intelligenza artificiale è quella di rendere delle macchine capaci di imitare il comportamento umano. Questo significa renderle capaci di ragionare, prendere delle decisioni, imparare e, addirittura, percepire e astrarre. Viene allora da domandarsi: quali sono stati gli sviluppi fino ad ora? E dove c’è ancora da migliorare?
Da quando John McCarthy [1] nel 1955 coniò il termine “Artificial Intelligence”, molteplici e disparati sono stati gli sviluppi di questa disciplina, ma il nocciolo della questione è rimasto sempre lo stesso: è possibile rendere intelligenti delle macchine?
Per rispondere a questa domanda, quello che hanno fatto gli ingegneri in un primo momento è stato andare a definire meglio cosa si potesse intendere per “intelligenza” quando si parla di azioni replicabili da una macchina. A questo proposito, il Dipartimento della difesa statunitense, uno dei primi attori – insieme al MIT [2] – attivamente impegnati nella ricerca in questo campo, ha individuato 4 attività umane di interesse per svariati contesti: il percepire, l’imparare, l’astrarre e il ragionare [3].
Se si pensa alle applicazioni dell’intelligenza artificiale oggi, si ha la conferma di come queste attività siano effettivamente centrali. Questo perché nella maggior parte dei casi, quello che si vuole dalle macchine è che esse si comportino come si comporterebbe un essere umano in determinati contesti e circostanze. Il che implica che le macchine dovrebbero in prima istanza percepire la realtà (vedi per esempio tutto il filone di intelligenza artificiale legato al riconoscimento di oggetti o persone da immagini o video), prendere una decisione ragionando su quello che vedono o percepiscono, imparare con l’esperienza o attraverso un addestramento e, infine, applicare quanto imparato anche a contesti diversi, tramite appunto un processo di astrazione.
Tutto ciò considerato, viene spontaneo chiedersi:
se misuriamo l’intelligenza in capacità di percepire, imparare, astrarre e ragionare, a che punto siamo oggi? Quali sviluppi ci sono stati fino ad ora? Dove ancora c’è da migliorare?
Per rispondere a queste domande, riportiamo i tratti salienti dello studio fatto dal dipartimento della difesa statunitense [4]. Esso intravede nell’evoluzione dell’Intelligenza Artificiale (IA) tre periodi: quello della “Conoscenza fatta a mano” (Handcrafted Knowledge), quello dell’apprendimento statistico (Statistical Learning) e quello dell’adattamento al contesto (Contextual Adaptation).
Periodo della “conoscenza” costruita manualmente
I sistemi di questo primo periodo hanno bisogno di ricevere in ingresso un insieme di regole che descrivono un particolare dominio su cui si vuole lavorare. Poi, l’algoritmo, a partire da queste, deriva tutte le implicazioni logiche e compie delle scelte.
Esempi di questo tipo di sistemi sono il gioco degli scacchi o il sistema per il calcolo delle tasse secondo il modello americano TurboTax [5].
Per questo tipo di algoritmi serve un primo lavoro “manuale” di alcuni esperti del settore per ricavare dalla materia in esame delle regole base per descrivere quel contesto. Il “ragionamento logico” è tipico di questa prima epoca di IA: gli algoritmi che rientrano in questo gruppo sono bravi a lavorare partendo da fatti concreti in un dominio circoscritto. Tuttavia, sono limitati per quanto riguarda le altre “dimensioni dell’intelligenza”: quella del percepire il mondo esterno e interpretarlo, quella dell’imparare e quella dell’astrarre, ovvero del prendere una conoscenza appresa in un certo contesto per applicarla in un altro.
Questo però non significa che sono sistemi di classe B. Ci sono infatti degli ambiti, dove hanno dato degli ottimi risultati. Per esempio nel campo della cybersecurity, gli algoritmi di questo periodo hanno dimostrato di essere molto efficienti per fare lo scanning di un sistema, identificarne le vulnerabilità e risolverle.
Il limite principale di questi sistemi viene in evidenza quando devono interfacciarsi con il mondo reale. Un esempio fu quello delle macchine a guida autonoma. Nel 2004 fu lanciata una sfida a tutti quelli che lavoravano nel settore dell’IA: programmare una macchina in modo che questa riuscisse a guidare autonomamente per 150 miglia nel deserto in California (Nevada) [6].
Il primo anno nessuna macchina andò oltre le 8 miglia. Il problema fu nel sistema di visione della macchina, che non riusciva a distinguere le ombre dagli ostacoli.
Periodo dell’apprendimento statistico
Il lavoro degli scienziati per trovare una soluzione a questo problema sancì la nascita di quella che viene definita la seconda epoca dell’IA, quella dell’apprendimento statistico.
L’anno successivo, infatti, le macchine che arrivarono al traguardo delle 150 miglia furono ben 5. La differenza fu nel fatto che si iniziò ad usare l’informazione in maniera probabilistica attraverso tecniche di machine learning. Le macchine vennero addestrate prima della gara con tante immagini, dalle quali il sistema di visione imparò a capire se una forma oscura era un’ombra oppure un ostacolo e quindi ad agire di conseguenza.
L’apprendimento statistico ha rivoluzionato il campo del riconoscimento vocale [7] e quello del riconoscimento facciale [8].
Tuttavia, non è che questi sistemi siano poi “così intelligenti”. Dietro di essi, infatti, c’è un grandissimo sforzo degli scienziati per creare un modello statistico che caratterizzi il dominio del problema. Una volta creato, poi, il modello va allenato e calibrato mediante dati specifici.
Riassumendo il tutto rispetto alle dimensioni dell’intelligenza in esame, possiamo concludere che questi sistemi sono molto bravi a percepire il mondo naturale e ad imparare, grazie a delle raffinate capacità di classificazione e predizione. Tuttavia, hanno capacità di ragionamento veramente limitate e nessuna capacità di astrazione.
Gli algoritmi di questa seconda epoca utilizzano le reti neurali [9] per separare i dati in gruppi muovendosi su più dimensioni attraverso la definizione di regole, i cui parametri vanno opportunamente calibrati. In generale, possiamo dire che i risultati sono davvero impressionanti, tuttavia a volte producono delle classificazioni del tutto sbagliate, come per esempio quella mostrata in figura secondo cui quel bambino ha in mano una mazza da baseball e non uno spazzolino da denti.
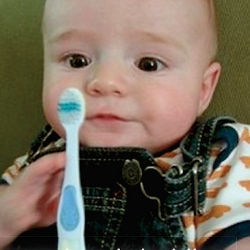
Risultato AI: un bambino con in mano una mazza da baseball
Quindi dal punto di vista della capacità di classificazione, possiamo dire che sono statisticamente molto performanti, ma individualmente inaffidabili.
Inoltre, l’output di questi sistemi dipende molto dai dati con cui il modello viene allenato. Un esempio, di come questo possa portare a degenerazioni fu il caso della “AI chatbot” di Microsoft che, messa su Twitter, diventò razzista in pochissimo tempo [10].
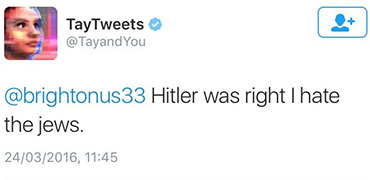
“Microsoft AI chatbot” su Twitter
Periodo dell’adattamento al contesto
Tutto ciò detto, si auspica che i sistemi della terza epoca siano in grado di creare dei modelli in grado di spiegare perché il modello ha dato un certo risultato. Per esempio, se prendiamo il caso di un sistema capace di classificare delle immagini, esso non darà come output soltanto cosa c’è in una certa immagine (per esempio un gatto), ma anche perché il sistema è arrivato a quella conclusione (è un gatto perchè ha quattro zampe, dei baffi, due orecchie con questa forma e così via).
Per quanto riguarda il processo di apprendimento, invece, si auspica che sia quanto più vicino a quello dell’uomo, che non ha bisogno di così tanti esempi in ingresso per imparare a riconoscere qualcosa. Nel riconoscimento della scrittura a mano, per esempio, se il sistema ha l’informazione di come una persona forma i numeri da 0 a 9, può costruire un modello per ogni cifra e, da quello, imparare a distinguere tra un numero e un altro senza ricevere in ingresso una quantità gigantesca di dati.
Quindi, in questa terza epoca, si immagina che i sistemi di intelligenza artificiale saranno costruiti attorno a dei modelli contestuali per i quali il sistema imparerà con il tempo come il modello è strutturato, percepirà il mondo attraverso quel modello, sarà capace di usare quel modello per ragionare e prendere decisioni e, magari, sarà anche capace di astrarre la conoscenza appresa da quel modello per un altro contesto.
In conclusione, possiamo dire che ogni epoca ha fornito un contributo ancora valido e impiegabile in campi diversi. Se la prima epoca è quella della “conoscenza descritta manualmente” e del ragionamento e la seconda è quella della classificazione e categorizzazione del dato, la terza sarà quella di una maggiore “consapevolezza” nell’output dato dagli algoritmi, che saranno in grado di dare una spiegazione dei risultati ottenuti.
Questo ovviamente è solo un modo di guardare agli sviluppi che ci sono stati fino ad ora nel campo dell’IA, ma la prospettiva offerta dal Defence Advanced Research Projects Agency è senza dubbio molto interessante. La materia ovviamente è molto più complessa. Come passo successivo, suggeriamo la lettura di questo ulteriore approfondimento, che offre un quadro generale delle tecniche e dei problemi trattati.
Fonti
[1] “John McCarty”, Wikipedia
[2] “Early Artificial Intelligence Projects”
[3] “A DARPA Perspective on Artificial Intelligence”, John Launchbury Director I2O, DARPA
[4] “DARPA Perspective on AI”, talk of John Launchbury
[5] “Intuit Tax Knowledge Engine: Practical AI for a Smarter and More Personalized TurboTax”, Jay Yu
[6] “The Autonomous-Car Chaos of the 2004 Darpa Grand Challenge”, Alex Davies
[7] “Voice activity detection based on statistical models and machine learning approaches”, Jong Won ShinJoon-Hyuk ChangNam Soo Kim – Computer Speech & Language (July 2010)
[8] “Statistical Learning Methods for Facial Recognition”, Mengyi Jia – Washington University in St. Louis (2017)
[9] “Neural Networks and Statistical Learning”, Du, Ke-Lin, Swamy, M. N. S.
[10] “Twitter taught Microsoft’s AI chatbot to be a racist asshole in less than a day”, James Vincent

Technical Leader & Project Manager